Formal Methods II
CSE3305
Practice Exam Notes From Lectures
Published Sunday, June 04, 2006 by Mathieu.
Practice exam:
i T. All NP complete problems are NP hard. (see section 3 of supp notes) Look at the stack. The NP-Complete problems contain some of the EXP, all the P and linear problems. The NP complete problems are the easiest of the NP-Hard problems.
iii) F - Kolmogorov complexity - length of a computer program to compute something, like sqroot 2. Or π. It's not - you can write something finite program to do it. Related to randomness. Shortest possible program to produce something. If that program is shorter than the string, then you have compressed the string.
Krafts inequality. Says that you can actually place proper codes in the tree so that its prefix.
iv F: {0, 1, 101} Violates Krafts inequality, because you have some binary tree with Some code with exactly these lengths,
ix) F There are far more random integers.
Something is algorithmically random
x)F (but won't ask a programming question like this)
Prob 2
Simplify
i O(1) It's a constant!
ii The whole thing goes to 1, (testing knowledge of limit theory)
v. Smaller terms dissapear
Something on information theory, but somewhat less
Euler problem - the perturbation of bridges (as opposed to city)
Perturbation operators
For the maximal clique problem: Like 2-opt or mutation or any number of things you can do to evaluate what to do next while searching.
Stochastic
Just means random - algorithms that have some random aspect to them. (Politics?) Just one bit aglorithmic RULE with some random variables. It would be predictable if all the pollys made the same decision in a predicable manner. But they don't so the algorithm as defined by each law becomes random!
There are degrees of randomness.
i T. All NP complete problems are NP hard. (see section 3 of supp notes) Look at the stack. The NP-Complete problems contain some of the EXP, all the P and linear problems. The NP complete problems are the easiest of the NP-Hard problems.
iii) F - Kolmogorov complexity - length of a computer program to compute something, like sqroot 2. Or π. It's not - you can write something finite program to do it. Related to randomness. Shortest possible program to produce something. If that program is shorter than the string, then you have compressed the string.
Krafts inequality. Says that you can actually place proper codes in the tree so that its prefix.
iv F: {0, 1, 101} Violates Krafts inequality, because you have some binary tree with Some code with exactly these lengths,
ix) F There are far more random integers.
Something is algorithmically random
x)F (but won't ask a programming question like this)
Prob 2
Simplify
i O(1) It's a constant!
ii The whole thing goes to 1, (testing knowledge of limit theory)
v. Smaller terms dissapear
Something on information theory, but somewhat less
Euler problem - the perturbation of bridges (as opposed to city)
Perturbation operators
For the maximal clique problem: Like 2-opt or mutation or any number of things you can do to evaluate what to do next while searching.
Stochastic
Just means random - algorithms that have some random aspect to them. (Politics?) Just one bit aglorithmic RULE with some random variables. It would be predictable if all the pollys made the same decision in a predicable manner. But they don't so the algorithm as defined by each law becomes random!
There are degrees of randomness.
Exam Study Notes, Topics, Concepts and Explanation
Published Saturday, June 03, 2006 by Mathieu.
Lecture 2: Analysing Algorithms
See the sample exam. The stuff with
Lecture 3: Search Problems
Lecture 4: Local Search Methods
Reward, error surface. Imagine your solutions as co ordinates, and you'll get a landscape.
Lecture 5: Partial Solution Search, I
Lecture 8: Probability
Transforming Distributions
Randomness and Information
Monte Carlo Simulation
There's part A, and part B
Part A
This is basically, say you have a blob, and it's too hard to work it out algebraically, so you draw a box around it, and poke it randomly, counting how many hits you get inside the blob.
Part B
is, you have a line on a graph, and you want to find the points between x and y on the x axis. You poke at random points along the line, and keep track of the average of the results you get from f(x) - the function. And you take that average is the area under the graph.
(see the napkin)
You select it randomly because this covers you if there's some regular pattern in the function.
Simulated Annealing
Temperature: The higher the temperature, the more likely the search will accept a move to a worse position in the search space (it always accepts improvements).
The search is done multiple times for progressively cooler temperatures, so the simulated annealing algorithm becomes less likely to accept worse positions as it continues to search.
Evolutionary Algorithms
Lecture 15: The Church-Turing Thesis
Lecture 16: P and NP
Lecture 17: NP Completeness
Probability
Distribution transformation
discreet random numbers
distribution
continuos, how is it different from discreet
Real numbers and integers are infinite, but the reals are a larger infinite!
Heuristic Evaluation.
This has to do with making a kind of educated guess as to the 'best next' state to visit.
L'Hospital's Rule
as n->inf f(x) / g(x) does something,
and this rule says as n->inf f'(x) / g'(x) does the same thing, which is handy when function are nasty.
Search
"Solution"
This term is used somewhat ambiguously in the subject. Generically means any point in the state space of the problem.
It could also mean:
Optimal Solution
A solution that maximises some evaluation criterion or function.
Candidate Solution
Assignment of values to variables which may or may not be optimal or matching a common goal. Hey, candidate solutions may even violate hard constraints! Which means they're infeasable - they're just not proper.
Constraints
Hard Constraints
State
For a system identified by a set of random variables, a state is a joint assignment of values to those variables.
For example:
Board Games The position on the board, plus whose turn it is.
TSP complete soln/ space search a permutation
TSP partial soln/ space search a permutation over a subset of cities.
Hmmm I'm not really getting these...
Apparently, The state space of a problem means the space of all possible joint assignments of values to variables.
Search Space
This is the all-mighty space which a search algorithm searches. Typically (but not always) the same as the state space for a problem. Often, we can do away with much of the search space because it's impossible for our answer to be in that space.
Local Search
This one is kind of intuitive. It works the way any old computing student would answer if you asked them how they think
Begins somewhere in the search space and looks for something better in the neighbourhood of that state, until we can do no better.
Can be either Deterministically greedy - examine every state, selecting the best or Stochastically greedy - randomly select some subset from the neighbourhood, selecting the best.
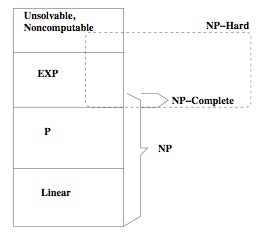
Complexity Theory
There's a handy diagram of the grand hierarchy of complexity theory. Although the one in the supplimentry notes isn't that clear... No wait I get it. It's not just badly formed LaTeX it's just, well, minimal.
We use this to give labels to problems (like, search problems), to put them in their category, and thus derive all kinds of delicious information about them from it.

Lets Read it!
NP-HARD Any NP problems that can be transformed within poly-time.
An NP-Hard problem is NP-Complete if it also happens to be NP (that's that little overlap there) But some NP-Hard problems are too hard to be in NP, meaning that their solutions require more than poly time to check.
NP problems which can be checked in polynomial time.
EXP stands for Exponential
P stands for polynomial - problems which can be solved in polynomial time.
Linear stands for .. whoops
All we need to do to check a proposed solution is try out each clause until one fails, or we get to the end, in which case, hooray! We've found our solution. We can do this in polynomial time.
But to actually solve a SAT, you have to go through each instantiation in the search space and apply that check routine to all such possible solutions. The solution space for the SAT is 2^n. Woweee Rik! We've got ourselves an NP-Hard problem where the best known solutions are exponential.
All this is really saying is that a check is elemental to one item in the search space, like our eval function, and to solve is to get the whole solution to a problem.
Cooks Theorem
iii) F - Kolmogorov complexity - length of a computer program to compute something, like sqroot 2. Or π. It's not - you can write something finite program to do it. Related to randomness. Shortest possible program to produce something. If that program is shorter than the string, then you have compressed the string.
Kraft's Inequality
Says that you can actually place proper codes in the tree so that its prefix.
Prefix Trees
Greedy Search
May be deterministic; making it blind.
Stochastic
A stochastic process is one whose behaviour is non-deterministic - the next state of the environment is not fully determined by the previous state of the environment. Stochastic search incorporates some degree of randomness.
At some decision points, we'll decide what to do next, yes, randomly!
Just means random - algorithms that have some random aspect to them. (Politics?) Just one bit aglorithmic RULE with some random variables. It would be predictable if all the pollys made the same decision in a predicable manner. But they don't so the algorithm as defined by each law becomes random!
There are degrees of randomness.
Examples:
Stochastic Hill Climber
2-opt
You might remember this one from that online java example of it. Looked at it a lot while trying to fathom assignment 2 so many Sundays ago.
Basically it randomly swaps two non adjacent edges
Greedy search with random restarts, GSAT too
Yes, it's that random restarting that's making it random.
Simulated Annealing
Evolutionary Algorithms
My personal favourite!
Genotype is what is inherited from gen to the next
Phenotype whatever develops out of that mating. Like in our case, height, intelligence, hair colour etc.
Normal Distribution
Deterministic Search
Is a search that will run the same steps every time it is given the same input. (A stochastic search will not).
Examples:
Dynamic Programming
Exhaustive Search
Dijkstra
BFS
DFS
A*
Greedy Search
Gradient Descent
Joel gave a good description for this one:
Normal local search finds a local minimum by (possibly randomly)
walking around looking for points that are lower.
Gradient descent does not immediately walk around; instead, it "looks"
at the land (search space) and figures out (usually mathematically)
which direction is downhill, and *then* walks.
It finds a local minimum much faster, but it's not always possible to
do this kind of calculation, which is why we still need ordinary local
search.
Hill Climbing
GSAT's inner loop
TABU search
Takes the best state in the neighbourhood, with the neighbourhood reduced by tabu considerations.
Greedy
Limit it by the number of solutions tested. They store the best answer so far, and when you reach the limit, return that.
LOTS of informal proofs in the lecture notes, so you can read them there.
Note that neither deterministic local search not stochastic algorithms can be complete. Local search get stuck at local optima (oh dear!) and the latter take a random step missing the global optimum. Supplementary Notes 3
Huffman Code
This is the only stuff I got down in lectures on Huffman code:
Wikipedia is ok, but this is also a good description.
a b c d e f
2/9 1/9 1/9 1/6 1/3 1/18
e a d b c f
| | |
5/19
What's That!?
Anyway, it seems like a nifty (say, genius) way of creating a table of symbols which can then be used to compress data in a lossless way!
It uses a variable length code table based on the estimated probability of occurrence for each possible source symbol. It's so nifty it uses a specific method to generate the code that is prefix free, and expresses the most occurring characters with a smaller strings of bits. You have to have a good estimation of the true probability value of each input symbol to get a good compression.
What a beautiful algorithm. It's so simple yet efficient.
Busy Beaver
Being an example a noncomputable function is pretty much all it's for.
There are two versions of the function, that both take a weeny little parameter, n.
One version is the largest number of 1s that can be written by a Turing machine with n states.
The other version is the largest number of steps (execution time) that can be taken by a Turing machine with n states.
In both cases only Turing machines which halt are allowed to be
considered.
(lecture on church turing)
Sigma (n) is not computable
produces biggest string of 1's
The point of the function is to have a direct and clear illustration of the non computable functions.
We can produce an enumeration of all turing machines.
AUTOSOUP/FLIB
Cantors Argument
there are infinite sets which cannot be put into one-to-one correspondance with the infinite set of natural numbers.
Maximal clique problem
Aleph-null
In case this is confusing anyone, aleph-null is "countable infinity",
i.e. how many natural numbers, or integers, or rationals there are.
Euler problem
the perturbation of bridges (as opposed to city)
Perturbation operators
For the maximal clique problem: Like 2-opt or mutation or any number of things you can do to evaluate what to do next while searching.
Stochastic
See the sample exam. The stuff with
Lecture 3: Search Problems
Lecture 4: Local Search Methods
Reward, error surface. Imagine your solutions as co ordinates, and you'll get a landscape.
Lecture 5: Partial Solution Search, I
Lecture 8: Probability
Transforming Distributions
Randomness and Information
Monte Carlo Simulation
There's part A, and part B
Part A
This is basically, say you have a blob, and it's too hard to work it out algebraically, so you draw a box around it, and poke it randomly, counting how many hits you get inside the blob.
Part B
is, you have a line on a graph, and you want to find the points between x and y on the x axis. You poke at random points along the line, and keep track of the average of the results you get from f(x) - the function. And you take that average is the area under the graph.
(see the napkin)
You select it randomly because this covers you if there's some regular pattern in the function.
Simulated Annealing
Temperature: The higher the temperature, the more likely the search will accept a move to a worse position in the search space (it always accepts improvements).
The search is done multiple times for progressively cooler temperatures, so the simulated annealing algorithm becomes less likely to accept worse positions as it continues to search.
Evolutionary Algorithms
Lecture 15: The Church-Turing Thesis
Lecture 16: P and NP
Lecture 17: NP Completeness
Probability
Distribution transformation
discreet random numbers
distribution
continuos, how is it different from discreet
Real numbers and integers are infinite, but the reals are a larger infinite!
Heuristic Evaluation.
This has to do with making a kind of educated guess as to the 'best next' state to visit.
L'Hospital's Rule
as n->inf f(x) / g(x) does something,
and this rule says as n->inf f'(x) / g'(x) does the same thing, which is handy when function are nasty.
Search
"Solution"
This term is used somewhat ambiguously in the subject. Generically means any point in the state space of the problem.
It could also mean:
Optimal Solution
A solution that maximises some evaluation criterion or function.
Candidate Solution
Assignment of values to variables which may or may not be optimal or matching a common goal. Hey, candidate solutions may even violate hard constraints! Which means they're infeasable - they're just not proper.
Constraints
Hard Constraints
State
For a system identified by a set of random variables, a state is a joint assignment of values to those variables.
For example:
Board Games The position on the board, plus whose turn it is.
TSP complete soln/ space search a permutation
TSP partial soln/ space search a permutation over a subset of cities.
Hmmm I'm not really getting these...
Apparently, The state space of a problem means the space of all possible joint assignments of values to variables.
Search Space
This is the all-mighty space which a search algorithm searches. Typically (but not always) the same as the state space for a problem. Often, we can do away with much of the search space because it's impossible for our answer to be in that space.
Local Search
This one is kind of intuitive. It works the way any old computing student would answer if you asked them how they think
Begins somewhere in the search space and looks for something better in the neighbourhood of that state, until we can do no better.
Can be either Deterministically greedy - examine every state, selecting the best or Stochastically greedy - randomly select some subset from the neighbourhood, selecting the best.
Complexity Theory
There's a handy diagram of the grand hierarchy of complexity theory. Although the one in the supplimentry notes isn't that clear... No wait I get it. It's not just badly formed LaTeX it's just, well, minimal.
We use this to give labels to problems (like, search problems), to put them in their category, and thus derive all kinds of delicious information about them from it.
Lets Read it!
NP-HARD Any NP problems that can be transformed within poly-time.
An NP-Hard problem is NP-Complete if it also happens to be NP (that's that little overlap there) But some NP-Hard problems are too hard to be in NP, meaning that their solutions require more than poly time to check.
NP problems which can be checked in polynomial time.
EXP stands for Exponential
P stands for polynomial - problems which can be solved in polynomial time.
Linear stands for .. whoops
A problem is in P if it can be solved in polynomial time on a deterministic Turing machine (think: ordinary computer). It's in NP if it can be solved in polynomial time on a nondeterministic Turing machine. That's harder to explain, but Cook proved that any problem in NP is reducible to 3-SAT, so it's in NP if it's reducible to (i.e. not harder than) an NP-complete problem.Use the SAT as an example.
Difference between checking and solving? (Robyn)
All we need to do to check a proposed solution is try out each clause until one fails, or we get to the end, in which case, hooray! We've found our solution. We can do this in polynomial time.
But to actually solve a SAT, you have to go through each instantiation in the search space and apply that check routine to all such possible solutions. The solution space for the SAT is 2^n. Woweee Rik! We've got ourselves an NP-Hard problem where the best known solutions are exponential.
All this is really saying is that a check is elemental to one item in the search space, like our eval function, and to solve is to get the whole solution to a problem.
Cooks Theorem
Speaking quite roughly what it does is turn any nondeterministicKolmogrov
Turing machine into input for the satisfiability problem, and shows
that if the machine halts in polynomial time, then this transformation
can also be done in polynomial time.
Since the definition of an NP problem is a problem that can be solved
in polynomial time on a nondeterministic Turing machine, this shows
that any NP problem can be transformed into input for the SAT problem
(in polynomial time), and so can't be harder than SAT. (Joel)
iii) F - Kolmogorov complexity - length of a computer program to compute something, like sqroot 2. Or π. It's not - you can write something finite program to do it. Related to randomness. Shortest possible program to produce something. If that program is shorter than the string, then you have compressed the string.
Kraft's Inequality
Says that you can actually place proper codes in the tree so that its prefix.
Prefix Trees
Greedy Search
May be deterministic; making it blind.
Stochastic
A stochastic process is one whose behaviour is non-deterministic - the next state of the environment is not fully determined by the previous state of the environment. Stochastic search incorporates some degree of randomness.
At some decision points, we'll decide what to do next, yes, randomly!
Just means random - algorithms that have some random aspect to them. (Politics?) Just one bit aglorithmic RULE with some random variables. It would be predictable if all the pollys made the same decision in a predicable manner. But they don't so the algorithm as defined by each law becomes random!
There are degrees of randomness.
Examples:
Stochastic Hill Climber
2-opt
You might remember this one from that online java example of it. Looked at it a lot while trying to fathom assignment 2 so many Sundays ago.
Basically it randomly swaps two non adjacent edges
Greedy search with random restarts, GSAT too
Yes, it's that random restarting that's making it random.
Simulated Annealing
Evolutionary Algorithms
My personal favourite!
Genotype is what is inherited from gen to the next
Phenotype whatever develops out of that mating. Like in our case, height, intelligence, hair colour etc.
Normal Distribution
Deterministic Search
Is a search that will run the same steps every time it is given the same input. (A stochastic search will not).
Examples:
Dynamic Programming
Exhaustive Search
Dijkstra
BFS
DFS
A*
Greedy Search
Gradient Descent
Joel gave a good description for this one:
Normal local search finds a local minimum by (possibly randomly)
walking around looking for points that are lower.
Gradient descent does not immediately walk around; instead, it "looks"
at the land (search space) and figures out (usually mathematically)
which direction is downhill, and *then* walks.
It finds a local minimum much faster, but it's not always possible to
do this kind of calculation, which is why we still need ordinary local
search.
Hill Climbing
GSAT's inner loop
TABU search
Takes the best state in the neighbourhood, with the neighbourhood reduced by tabu considerations.
Greedy
Limit it by the number of solutions tested. They store the best answer so far, and when you reach the limit, return that.
LOTS of informal proofs in the lecture notes, so you can read them there.
Note that neither deterministic local search not stochastic algorithms can be complete. Local search get stuck at local optima (oh dear!) and the latter take a random step missing the global optimum. Supplementary Notes 3
Huffman Code
This is the only stuff I got down in lectures on Huffman code:
Wikipedia is ok, but this is also a good description.
a b c d e f
2/9 1/9 1/9 1/6 1/3 1/18
e a d b c f
| | |
5/19
What's That!?
Anyway, it seems like a nifty (say, genius) way of creating a table of symbols which can then be used to compress data in a lossless way!
It uses a variable length code table based on the estimated probability of occurrence for each possible source symbol. It's so nifty it uses a specific method to generate the code that is prefix free, and expresses the most occurring characters with a smaller strings of bits. You have to have a good estimation of the true probability value of each input symbol to get a good compression.
What a beautiful algorithm. It's so simple yet efficient.
Is mp3 compression really lossy? If the only information taken from the recording is that that human ears can't hear anyway, is that really information loss? After all, if there's music playing in a forest, and there's nobody there to hear it, is there any music at all?Huffman encoding is really useful. It's NOT lossy. Compression is really useful.
Busy Beaver
Being an example a noncomputable function is pretty much all it's for.
There are two versions of the function, that both take a weeny little parameter, n.
One version is the largest number of 1s that can be written by a Turing machine with n states.
The other version is the largest number of steps (execution time) that can be taken by a Turing machine with n states.
In both cases only Turing machines which halt are allowed to be
considered.
(lecture on church turing)
Sigma (n) is not computable
produces biggest string of 1's
The point of the function is to have a direct and clear illustration of the non computable functions.
We can produce an enumeration of all turing machines.
AUTOSOUP/FLIB
Cantors Argument
there are infinite sets which cannot be put into one-to-one correspondance with the infinite set of natural numbers.
Maximal clique problem
Aleph-null
In case this is confusing anyone, aleph-null is "countable infinity",
i.e. how many natural numbers, or integers, or rationals there are.
Euler problem
the perturbation of bridges (as opposed to city)
Perturbation operators
For the maximal clique problem: Like 2-opt or mutation or any number of things you can do to evaluate what to do next while searching.
Stochastic
Search Algorithms
Published Thursday, May 04, 2006 by Mathieu.
Could be in 試験
f(a)
..... O(a)
log2 a
You have to think of the input SIZE not the input VALUE.
So the proper complexity would be O(2^a)
ie
g(x) = { O(x) x prime
O(x^2) Not prime
-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
Local Optima
When you throw those techniques at local optima, you get local optima! So you can use generic local search to try and get yourself out of this.
Greedy Search
You have a partial solution, and you build up a complete solution from that.
Local search is greedy.
Systematic or exhaustive searches are not greedy.
Dijkstras. etc. It can escape local optima.
Korbs version of MF's Chapter 5
Iterated Hill Climber
Stochastic hill climber
f(a)
..... O(a)
log2 a
You have to think of the input SIZE not the input VALUE.
So the proper complexity would be O(2^a)
ie
g(x) = { O(x) x prime
O(x^2) Not prime
-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
Local Optima
When you throw those techniques at local optima, you get local optima! So you can use generic local search to try and get yourself out of this.
Greedy Search
You have a partial solution, and you build up a complete solution from that.
Local search is greedy.
Systematic or exhaustive searches are not greedy.
Dijkstras. etc. It can escape local optima.
Korbs version of MF's Chapter 5
Iterated Hill Climber
Stochastic hill climber
Simulations
Published by Mathieu.
Why simulate?
We're being showed techniques for
The fraction of problems that can be solved exactly with a sane amount of effort is quite small. -N. Gershenfeld.
Answer: Why work hard when a slave (computer simulation) can do it for you?
We've already given up on exactness!
So what can we do?
1. Analytic Integration
2. Numerical Integration.
Computationally intensive in multiple dimensions.
Analog Computation
It's not that bad if you can draw accurately! You can get an approximation of the answer.
Monte Carlo Integration
It's particularly efficient and accurate, especially for high dimensional functions, as long as the function is reasonably well behaved.
Integral can be estimated by randomly selecting n points and taking the average.
So all slide 10 is saying is that you are taking the average of it
.
.
...................................
.
. this area
.
...................................
a b
Monte Carlo Integration directly applies to multidimensional f.
13
Buffon was tossing needles and used this to come up with an estimation of π.
Turns out that they needed only really small sample sizes. But it turned out that they weren't estimating π at all!
So it doesn't really work if you know the answer already. That's what he means by, if you just stare at these numbers, you never really know when you're done.
You should do repeated examples and estimate variance. If it's .0025, you'll have 3 digit accuracy, and you're done.
16
What do you do about controlling your variance?
Increase the sample size! If you do this enough, you'll eventually get convergence. But with complex problems, you could be waiting billions of years for this.
Just showing that variance is controlled by sample size. Variance decreases directly proportional to the sample size.
Pseudo random numbers are simply too random! In 2 dimensional random noise, you still get clumps and stuff which are radiation and gravitation of super galaxies etc on a TV, for example.
In quasi-random, we help them clump together quicker.
We are just being pointed to these techniques.
18
Random walks have been used to model even such things as the stock market.
neo-conservatives
Some other applications of random walks
Behaviour of liquids and gasses in physics.
We're being showed techniques for
The fraction of problems that can be solved exactly with a sane amount of effort is quite small. -N. Gershenfeld.
Answer: Why work hard when a slave (computer simulation) can do it for you?
We've already given up on exactness!
So what can we do?
1. Analytic Integration
2. Numerical Integration.
Computationally intensive in multiple dimensions.
Analog Computation
It's not that bad if you can draw accurately! You can get an approximation of the answer.
Monte Carlo Integration
It's particularly efficient and accurate, especially for high dimensional functions, as long as the function is reasonably well behaved.
Integral can be estimated by randomly selecting n points and taking the average.
So all slide 10 is saying is that you are taking the average of it
.
.
...................................
.
. this area
.
...................................
a b
Monte Carlo Integration directly applies to multidimensional f.
13
Buffon was tossing needles and used this to come up with an estimation of π.
Turns out that they needed only really small sample sizes. But it turned out that they weren't estimating π at all!
So it doesn't really work if you know the answer already. That's what he means by, if you just stare at these numbers, you never really know when you're done.
You should do repeated examples and estimate variance. If it's .0025, you'll have 3 digit accuracy, and you're done.
16
What do you do about controlling your variance?
Increase the sample size! If you do this enough, you'll eventually get convergence. But with complex problems, you could be waiting billions of years for this.
Just showing that variance is controlled by sample size. Variance decreases directly proportional to the sample size.
Pseudo random numbers are simply too random! In 2 dimensional random noise, you still get clumps and stuff which are radiation and gravitation of super galaxies etc on a TV, for example.
In quasi-random, we help them clump together quicker.
We are just being pointed to these techniques.
18
Random walks have been used to model even such things as the stock market.
neo-conservatives
Some other applications of random walks
Behaviour of liquids and gasses in physics.
Lecture
Published by Mathieu.
Venn’s identity “probability = frequency” clearly fails
in small samples.
(or 1) just because the coin
was only flipped once.
von Mises moved to probabilities as limit frequencies in
large samples.
Definition of a collective:
An infinite sequence of outcomes S = (s1, ...., Sn, ...) of a repeatable experiment (where {si} is the set of all its possible outcomes), satisfying the conditions:
1. Axiom of Convergence
Let be the set of all possible outcomes of a repeat-
able experiment. Let the sequence be
composed of outcomes in that set (each for some
). Assuming satisfies von Mises’ definition for a
collective, show that the corresponding probability function
satisfies Kolmogorov’s axioms for a probability function.
That is, taking defined over all the singleton sets of out-
comes and their unions, show that it satisfies
in small samples.
(or 1) just because the coin
was only flipped once.
von Mises moved to probabilities as limit frequencies in
large samples.
Definition of a collective:
An infinite sequence of outcomes S = (s1, ...., Sn, ...) of a repeatable experiment (where {si} is the set of all its possible outcomes), satisfying the conditions:
1. Axiom of Convergence
Let be the set of all possible outcomes of a repeat-
able experiment. Let the sequence be
composed of outcomes in that set (each for some
). Assuming satisfies von Mises’ definition for a
collective, show that the corresponding probability function
satisfies Kolmogorov’s axioms for a probability function.
That is, taking defined over all the singleton sets of out-
comes and their unions, show that it satisfies
Information Theory
Published Friday, April 28, 2006 by Mathieu.
Information Theory
Core of Computer Science!
It is the basis of coding theory. Which is very practical, storage, transmission, telecommunications etc, Which is where it arose.
Optimal Codes
Maximally efficient codes.
You minimise the average code length
Huffman codes
Simple alg.
Will construct a code that is optimal. And will therefore satisfy shannon's rule.
As you increase the block size, the huffman code becomes more efficient.
Next lecture:
Entropy
"The average information in a code"
It is non negative.
The more uncertainty the greater the entropy.
Channel Capacity
Core of Computer Science!
It is the basis of coding theory. Which is very practical, storage, transmission, telecommunications etc, Which is where it arose.
Optimal Codes
Maximally efficient codes.
You minimise the average code length
Huffman codes
Simple alg.
Will construct a code that is optimal. And will therefore satisfy shannon's rule.
As you increase the block size, the huffman code becomes more efficient.
Next lecture:
Entropy
"The average information in a code"
It is non negative.
The more uncertainty the greater the entropy.
Channel Capacity
Randomness
Published Wednesday, April 26, 2006 by Mathieu.
Prob 3:
w is a number
The questions are not about c and h, they are presumed to be given relative to some problem.
The answers are intended to be in when and only when w is in the interval a, b where a and b is specified, of course.
The answer might be never!
Problem 1, part 3.
Problem 4
i.
ii. are too easy
the heart of the 問題 is in iii.
Lecture 10.
Cover and Thomas can be used as a reference to this section of the lectures.
What is randomness? An event is random iff it is produced by an indeterministic process.
But then,
Everything is random
Or nothing is. (there is no such thing as an indetermanism)
We'll leave that to philosophy and physics.
We think about the computer science side of things.
The star is to indicate how long these bit strings might be.
ごく普通の英語で説明してみたらどう?もっと覚えるかもしれない。
You can compress the bit string that represents pi, it's just a program that generates the string (it's got to be smaller than infinity!)
Algorithmic randomness
Computable numbers (at large expansions) are by definition algorithmically non-random!
Cantors Diagonal Argument
Something every CS should know!
You just have to imagine that you have a list of all real and bit string numbers.
Turing - "There are Non computable numbers"
We suppose that all these numbers are computable.
There has to be a program to compute it.
Let's enumerate all possible programs.
We can't enumerate their output, but we can pretend.
We can't actually get a real random number, because they're uncomputable. So we have to put up with almost or good enough randomness that we can compute.
We more random something is, the less information there is.
English and Logic are inefficient because there is more than one way to say the same thing. Which is an indirect way of saying that it can't satisfy shannon information.
w is a number
The questions are not about c and h, they are presumed to be given relative to some problem.
The answers are intended to be in when and only when w is in the interval a, b where a and b is specified, of course.
The answer might be never!
Problem 1, part 3.
Problem 4
i.
ii. are too easy
the heart of the 問題 is in iii.
Lecture 10.
Cover and Thomas can be used as a reference to this section of the lectures.
What is randomness? An event is random iff it is produced by an indeterministic process.
But then,
Everything is random
Or nothing is. (there is no such thing as an indetermanism)
We'll leave that to philosophy and physics.
We think about the computer science side of things.
The star is to indicate how long these bit strings might be.
ごく普通の英語で説明してみたらどう?もっと覚えるかもしれない。
You can compress the bit string that represents pi, it's just a program that generates the string (it's got to be smaller than infinity!)
Algorithmic randomness
Computable numbers (at large expansions) are by definition algorithmically non-random!
Cantors Diagonal Argument
Something every CS should know!
You just have to imagine that you have a list of all real and bit string numbers.
Turing - "There are Non computable numbers"
We suppose that all these numbers are computable.
There has to be a program to compute it.
Let's enumerate all possible programs.
We can't enumerate their output, but we can pretend.
We can't actually get a real random number, because they're uncomputable. So we have to put up with almost or good enough randomness that we can compute.
We more random something is, the less information there is.
English and Logic are inefficient because there is more than one way to say the same thing. Which is an indirect way of saying that it can't satisfy shannon information.
Assignment 2 Hints
Published Sunday, April 23, 2006 by Mathieu.
(i) Theoretic union for everything
(ii) Basically working with limits and infinite sequences etc.
It doesn't have to be a proof - if it's a clear argument then that's ok.
TSP problem
In each case you figure out the best and worst case, define in those terms, and exemplify by showing how it could be the best case. Find a graph where that happens and then indicate how that happens.
Problem 3.
Take the evel function, throw in a weight. the expresions are
Complete: If there is a definition, in the search space, it will find it eventually.
Problem4
Fuel costs etc. YOu can have a heuristic graph next to it. When you're doing with
(ii) Basically working with limits and infinite sequences etc.
It doesn't have to be a proof - if it's a clear argument then that's ok.
TSP problem
In each case you figure out the best and worst case, define in those terms, and exemplify by showing how it could be the best case. Find a graph where that happens and then indicate how that happens.
Problem 3.
Take the evel function, throw in a weight. the expresions are
Complete: If there is a definition, in the search space, it will find it eventually.
Problem4
Fuel costs etc. YOu can have a heuristic graph next to it. When you're doing with
Lecture: Probability 2
Published Sunday, April 09, 2006 by Mathieu.
Expectation Functions or operators
Law of large numbers.
In a statistical context, laws of large numbers imply that the average of a random sample from a large population is likely to be close to the mean of the whole population.
(WPedia)
Binomial Distribution
Coin tosses
random bit strings
computer storage
computer programs (when translated into computer programs)
"In probability theory and statistics, the binomial distribution is the discrete probability distribution of the number of successes in a sequence of n independent yes/no experiments, each of which yields success with probability p. Such a success/failure experiment is also called a Bernoulli experiment or Bernoulli trial. In fact, when n = 1, then the binomial distribution is the Bernoulli distribution. The binomial distribution is the basis for the popular binomial test of statistical significance."
WP
B(n, p)
poisson Distribution
The number of visitors to a web page, the number of objects sent in a Java program.
The sole parameter is Lambda.
Lambda = 5:
Means that the poisson peaks on 5.
Uniform Distributions (the most boring!)
Can have a discreet case or continuous case.
Normal Distribution
The central limit therom shows that when you're modeling preactically anything you can get the mean (which is usually the most important thing you want).
Pseudo-random Numbers
We live as CS students in the land of fake - so we have to somehow generate random numbers for our simulations.
Law of large numbers.
In a statistical context, laws of large numbers imply that the average of a random sample from a large population is likely to be close to the mean of the whole population.
(WPedia)
Binomial Distribution
Coin tosses
random bit strings
computer storage
computer programs (when translated into computer programs)
"In probability theory and statistics, the binomial distribution is the discrete probability distribution of the number of successes in a sequence of n independent yes/no experiments, each of which yields success with probability p. Such a success/failure experiment is also called a Bernoulli experiment or Bernoulli trial. In fact, when n = 1, then the binomial distribution is the Bernoulli distribution. The binomial distribution is the basis for the popular binomial test of statistical significance."
WP
B(n, p)
poisson Distribution
The number of visitors to a web page, the number of objects sent in a Java program.
The sole parameter is Lambda.
Lambda = 5:
Means that the poisson peaks on 5.
Uniform Distributions (the most boring!)
Can have a discreet case or continuous case.
Normal Distribution
The central limit therom shows that when you're modeling preactically anything you can get the mean (which is usually the most important thing you want).
Pseudo-random Numbers
We live as CS students in the land of fake - so we have to somehow generate random numbers for our simulations.
Last posts
Archives
Links
- JPS2150 Identity and Tradition
- CSE3308 Analysis and Design
- CSE3305 Formal Methods II
- CSE3395 Perl Programming
- CSE3391 Unix Tools
- Monash University
- my.monash
- Mathieutozer.com
- Courseware Page